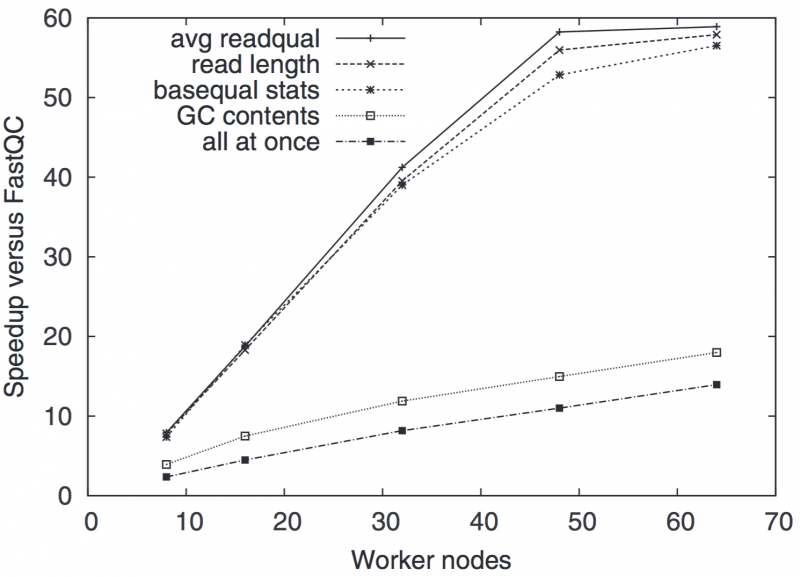
Next generation sequencing (NGS) data sets are growing quickly and are already one of the largest instances of big data in science. We have developed SeqPig [1] a simple to use scripting framework that automatically parallelizes NGS data processing tasks using the Hadoop big data processing framework. This enables a simple way for scientists to exploit parallel cloud computing capacity for genomics data processing.
[1] Schumacher, A., Pireddu, L., Niemenmaa, M., Kallio, A., Korpelainen, E., Zanetti, G., and Heljanko, K.: SeqPig: Simple and scalable scripting for large sequencing data sets in Hadoop. Bioinformatics 30 (1): 119-120, 2014.
Last updated on 3 Oct 2014 by Maria Lindqvist - Page created on 12 Sep 2014 by Maria Lindqvist